vLLM: Serve LLMs at scale
This environment uses the vLLM serving engine to provide a high-performance deployment for serving large language models at scale.
Features
- Pre-configured vLLM server that can run your specified model
- OpenAI-compatible API endpoint
- Easy configuration through environment variables
- Support for custom SSL certificates
- Built-in benchmarking tools
Capabilities
Benchmarking Llama 3.1 8B (fp16) on our 1x RTX 3090 instance suggests that it can support apps with thousands of users by achieving reasonable tokens per second at 100+ concurrent requests.
The chart below shows that for 100 concurrent requests, each request gets worst case (p99) 12.88 tokens/s, resulting in a total tokens/s of 1300+!
p99 tokens per second
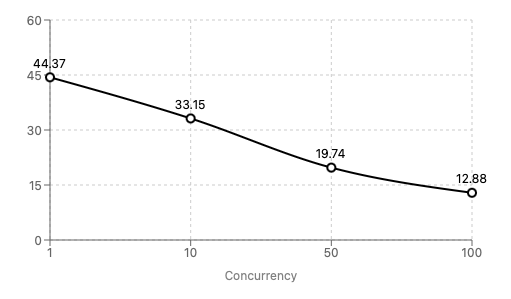
See the raw results here.
Note that this used a simple low token prompt and real world results may vary.
Using the server
The vLLM server can be accessed at the following URL: http://<your-instance-public-ip>:8000/v1
Replace <your-instance-public-ip> with the public IP of your Backprop instance. Use https if you have that configured.
Example request:
curl http://<your-instance-public-ip>:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer token-abc123" \
-d '{
"model": "NousResearch/Meta-Llama-3.1-8B-Instruct",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Translate to French: Hello, how are you?"
}
]
}'Please see the vLLM API Reference for more details.
Configuration
You can customize the vLLM server configuration using the following environment variables:
MODEL_NAME: The name of the Huggingface model to load (default: "NousResearch/Meta-Llama-3.1-8B-Instruct")API_KEY: API key for authentication (default: "token-abc123")GPU_MEMORY_UTILIZATION: GPU memory utilization (default: 0.99)TENSOR_PARALLEL_SIZE: Number of GPUs to use for tensor parallelism (default: 1)MAX_MODEL_LEN: Maximum sequence length - lower values use less GPU VRAM (default: 50000)USE_HTTPS: Set to "true" to enable HTTPS with a self-signed certificate (default: "false")
You can update these variables when launching the environment.
Custom SSL Certificates
If you want to use custom SSL certificates instead of the auto-generated ones, you can replace the following files:
/home/ubuntu/.vllm/ssl/cert.pem: Your SSL certificate/home/ubuntu/.vllm/ssl/key.pem: Your SSL private key
After replacing these files, restart the vLLM service for the changes to take effect.
Advanced Configuration
To update the vLLM server configuration:
- Modify the environment variables as needed (see above).
- Edit the systemd service file if necessary:
sudo nano /etc/systemd/system/vllm.service - After making changes, reload the systemd daemon and restart the service:
sudo systemctl daemon-reload sudo systemctl restart vllm
Viewing Logs
To view the vLLM server logs, you can use the following command:
sudo journalctl -u vllm -fThis will show you the live logs of the vLLM service.
Benchmarking
This environment comes with built-in benchmarking tools (see repo). You can find the benchmarking scripts in the /home/ubuntu/vllm-benchmark directory.
To run a benchmark:
cd /home/ubuntu/vllm-benchmark
python vllm_benchmark.py \
--vllm_url "http://<your-instance-public-ip>:8000/v1" \
--api_key "your-api-key"\
--num_requests 100 --concurrency 10Further Documentation
For more detailed information about vLLM and its OpenAI-compatible server, please refer to the official vLLM documentation.